
Merhaba değerli okuyucular, bu yazımda geçtiğimiz dönem görmüş olduğumuz ‘Otomata Teorisi’ ya da diğer isimleriyle ‘Automata Theory’,’Computer Theory’ olarak adlandırılan derste verilmiş olan ödevi ve çözümünü paylaşacağım.

Regular Expression(Regex) nedir?
Soruya geçmeden önce regex’in ne olduğunu anlamak çok önemli lütfen burayı atlamadan okuyun.Regular expression türkçeye düzenli ifade olarak çevrilmiştir. Düzenli ifade, sonlu otomata tarafından kabul edilen string ya da dil olarak tanımlanabilir. Tanım yerine bir örnekle açıklamak daha iyi olacaktır.
Örneğin kullanıcıdan istediğiniz formata uygun karakter dizisi ya da string almak istiyorsunuz.E-posta adı kontrolü bu örneğimiz için uygun bir testcase. Peki girilen e-posta’nın doğru olup olmadığını nasıl kontrol edersiniz? Örneğin içerisinde sadece 1 tane ‘@’ işareti olmalı ve kesinlikle içermeli ayrıca başta veya sonda olamaz.Büyük harf içeremez, sadece 1-9 arası sayılar ve a-z’ye harfler içebilir gibi birden çok kontrol etmemiz gereken durum olabilir.Peki bu kadar durumu nasıl programımıza entegre edeceğiz.Kesinlikle yapılabilir fakat çok zahmetli olduğu aşikar.Peki bu ifadeleri kontrol etmenin daha kolay bir yolu yok mu? Bu problemin çözümü için bizden önce düşünenler olmuş ve buna regular expression(düzenli ifade) adını vermişler.Daha detaylı anlamak için aşağıdakı yazıyı okumanızı ve bu videoyu izlemenizi öneririm.
Regex Tutorial: https://medium.com/factory-mind/regex-tutorial-a-simple-cheatsheet-by-examples-649dc1c3f285
Verilen alfabeye ve regular expressiona göre kelime nasıl üretilir?
Soruyu daha iyi anlamak için yazalım.
Dışarıdan S={a,b} şeklinde alfabeyi alan (virgül ile ayrılmış),
Düzenli ifadenin ne olacağını da kullanıcının belirlediği,
Nihayetinde L kelimelerin dilini üretebilme kabiliyetine sahip ve ekranda kullanıcının istediği kadar kelimeyi görüntüleyen program kodunu üretiniz.
Not: Düzenli ifadenin alfabeden üretilebilir olmasını kontrol etmelidir!
Not: Verilen kelimenin L diline ait olup olmadığını kontrol edebilen ödevlere bonus verilecektir!
Örnek:
Alfabeyi giriniz S={a,b}
Düzenli ifadeyi giriniz: (a+b)*a
L dilinin kaç kelimesini görmek istiyorsunuz? : 3
Düzenli ifade S alfabesinden üretilebilir. Kelimeleriniz listeleniyor..
L={a,aa,ba}
BONUS: Kontrol edilecek kelimeyi giriniz: b
ÇIKTI: Bu kelime L diline ait değildir.
NOT: Regex kütüphanesinin kullanımı yasaktır.Başlamadan önce Prestij filminden çok hoşuma giden bir sözü sizinle paylaşmak istiyorum. ”Anlatman için peşinden koşarlar ama söylediğin anda gözlerinde bir hiç olursun, bir hiç. Sır hiç kimseyi etkilemez ama kullandığın hile her şeydir.” Açıkcası sihirbaz numaları hepimizin hoşuna gidiyordur, fakat arkasındaki sırrı öğrenince yapılan numaranın sıradan olduğunu anlıyoruz. Bugün sorunun çözümüne de ulaştığınızda aslında sorunun çokta zor olmadığını anlayacaksınız. Asıl önemli olan kısım sorunun çözümüne ulaşıncaya kadar geçen zaman(En azından benim için 🙂 ).Umarım size keyifli bir okuma deneyimi sunabilirim. Yazının sonunda görüşlerinizi paylaşmayı unutmayın. İyi okumalar.
Bu soru bize ‘Otomata Teorisi’ altında 4. hafta yani regular expressionların anlatıldığı derste verilmişti. Zannediyorum ki sadece regex’i bilerek bu sorunun üstesinden gelinemez. Şayet dfa(deterministik sonlu otomat) ve nfa(nondeterministik sonlu otomat) konularında eksiğiniz varsa öncelikle onlara göz atmalısınız.Soruyu ilk gördüğümde epey şaşırmıştım ve işin içinden nasıl çıkacağımı saatlerce düşünmüştüm.Düzenli ifadeye uygun kelimeler nasıl üretilecek? kelimeler sonsuza gidiyor dolayısıyla önceki ürettiğini tekrar üretmemeli? peki üretmeyecekse ürettiklerimizi listede mi tutacağız? peki kelimelerin doğru olup olmadığını nasıl kontrol edeceğiz? 1 Hafta boyunca regex,dfa,nfa ve otomat makineleri ilgili araştırmalar yaptım.Soruyu çözebilmek için ‘Compiler Desing’ dersleri izledim.Github’da gezmediğim repo kalmadı. Bu konuyla alakalı Stackoverflow’da okumadığım yazı kalmadı denilebilir. ‘Sabreden derviş muradına ermiş’ atasözünden ilham alarak çözüme ulaştım.Umarım sizlere de çözümü güzel bir şekilde aktarabilirim.
NOT: Lütfen çözüme geçmeden önce kendiniz çözmeyi deneyin.Problemi çözebildiyseniz sizi tebrik ediyorum, araştırıp geliştirerek daha iyi yerlere gelebileceğinize inanıyorum.Şayet çözemediyseniz üzülmeyin çünkü çözümü öğrendiğinizde kendinize bilmediğiniz yeni bir şey daha katmış olacaksınız.
Soruyu adım adım inceleyelim
Düzenli ifadeyi giriniz: (a+b)*a
L dilinin kaç kelimesini görmek istiyorsunuz? : 3 (NOT: ‘+’ simgesi ‘veya’ anlamına gelmektedir.Farklı yazılarda farklı anlamlar ifade edebildiğinden dolayı anlam karışıklığının önüne geçmiş olalım.)
Çözümdeki en kritik nokta; regular expression’a uygun kelime üretme algoritması.
Peki bunun otomatlarla bağlantısı ne? Öncelikle buna bakalım.
(a+b)* şeklinde verilen düzenli ifadeden üretilebilen birkaç tane örnek çıktı yazalım -> a,b,aa,ab,ba,bb,aaa,aab,aba,abb,baa,bab… şeklinde gidiyor.
Şimdi de tersine mühendislik yapalım; ‘aab’ kelimesinin (a+b)* düzenli ifadesine uygun olup olmadığını nasıl anlarız? (a+b)* ifadesinin otomatını oluşturursak verilen ‘aab’ kelimesinin bu düzenli ifadeye uygun olup olmadığını anlayabiliriz.
Aslında burada güzel bir çıkarım yapmış oluyoruz. İnternette görmüş olduğunuz regexler bu mantıkta çalışıyor. En basit şeklinde anlatmak gerekirse(daha sonra ayrıntısına gireceğiz) girmiş olduğunuz regex’in otomatı çiziliyor, verilen kelimenin bu düzenli ifadeye ait olup olmadığı otomat üzerinden test ediliyor. Siz de FSM Simulator sitesi ile istediğiniz bir regex’in dfa-nfa-enfa’sını oluşturup girdiğiniz stringin adım adım sonlu otomata uygun olup olmadığını görsel şekilde kontrol edebilirsiniz.
Soruda verilen ufak trik:
Aslında sorunun bonus kısmını çözmüş olduk; Yani verilen düzenli ifadenin otomatını program aracılığı ile çıkartmamız gerekiyor. Daha sonra
BONUS: Kontrol edilecek kelimeyi giriniz: b <ENTER>Kontrol edilecek kelimeyi girerek otomat üzerinde bu düzenli ifadeye uygun mu? değil mi? kontrolü yapmamız gerekiyor. Yukarıda size vermiş olmuduğum FSM Simulator sitesinin aynısı olduğunu görebilirsiniz.Aslında soruda verilmiş olan bu ufak bonus soru bize çözüme ulaşmada trik vermiş oluyor.Daha sonra nasıl olduğunu anlayacağız.
Ama soruda bizden düzenli ifadeye uygun kelimeler üretmemiz isteniyor?
Acele etmeye gerek yok. Adım adım ilerlemek sorunun çözümünü anlamakta fayda sağlayacak. Şuana kadar sadece verilen string’in regex’e uygun olup olmadığını test edebilecek duruma geldik.Sırada açılması gereken son birkaç düğüm kaldı.Bunlardan ilki regex’in kullanım amacını anlamak.
Regular Expression’un kullanım amacını anlayalım: Yazının başında verdiğim e-posta adının doğrulunu kontrol etme örneğinden devam edersek;
Burada yaptığımız iş, verilen e-posta adının kurallara uyup uymadığını test etmek. Kurallara uyan kelimeler üretmek değil! Peki kelime nasıl üreteceğiz? Cevabı çokta zor değil. Verilen alfabeden rastgele kelimeler üreteceğiz ve verilen regex’e uygun olup olmadığını test edeceğiz. Kurallara uyan kelimeleri de saklayarak kullanıcıya göstereceğiz. Zaten soru da bizden bu noktanın anlaşılmasını istiyor. Regex hafızada birşeyler saklamaz, kelime üretmez. Sonlu otomatlarda da gördüğümüz üzere kelime’nin final state’ine ulaşıp ulaşamadığını kontrol eder.
Verilen alfabeden tüm kelime kombinasyonlarını üretme
Yapacağımız işi daha iyi anlaşılması için örnekleyelim;
Alfabeyi giriniz:
S={ a,b }
L={a,aa,ba}
<ENTER>Alfabeden kelimeler üretmemiz gerekiyor. Örnekte görebileceğimiz üzere en küçük uzunluktan başlayarak üretilen kelimeleri kabul etmiş. Yani alfabenin bütün kombinasyonlarını küçükten başlayarak üreten kodu yazmamız gerekiyor. Örnek vermek gerekirse {a,b} alfabesi için -> a,b,aa,ab,ba,bb,aaa,aab,aba,baa,bab,bbb… şeklinde bütün kombinasyonları üreterek test edeceğiz ve regex’e uyanları saklayacağız.
NOT: Çözüme geçmeden önce kendiniz kodlamayı denemeniz tecrübe katacaktır.
Bunu da n’lik sayı sistemi mantığını kullanarak yapacağız. Mantığı anlamak için örnek verelim; ( n = alfabenin uzunluğu )
0 sayısı ‘a’ harfini temsil etsin, 1 sayısı da ‘b’ harfini. 0’dan başlayarak sırasıyla bütün pozitif tam sayıları n’lik sayı sistemine çevirelim.Bu örnekte alfabe {a,b} olduğundan dolayı n = 2 oluyor.
0 sayısının 2'lik tabandaki karşılığı -> 0 (a)
1 sayısının 2'lik tabandaki karşılığı -> 1 (b)
2 sayısının 2'lik tabandaki karşılığı -> 10 (ba)
3 sayısının 2'lik tabandaki karşılığı -> 11 (bb)
4 sayısının 2'lik tabandaki karşılığı -> 100 (baa)
5 sayısının 2'lik tabandaki karşılığı -> 101 (bab)Yukarıda görüldüğü üzere bir kısım kombinasyonları elde etmemiz mümkün. Fakat dikkatli şekilde ürettiğimiz 2 uzunluğundaki kombinasyonlara bakalım( ba ve bb). Halbuki biz aa,ab kelimelerini de üretmek istiyoruz.Bunların üretilememe nedeni baştaki 0’ların değersiz olduğundan dolayı yazılmamasından kaynaklanıyor. Örneğin ikilik tabanda 5 yazarken ‘101’ şeklinde yazıyoruz, başına 0 koyarak yazmıyoruz -> ‘0101’. Dolayısıyla tüm kombinasyonları doğru bir biçimde üretmek için bir tane boş kelime koyarak üretim yapmak zorundayız.Bu şekilde yaparak başına değersiz olan 0’ı boş kelimeyle sağlamış olacağız.Örnek vermek gerekirse {a,b} şeklinde alfabede başına boş bir kelime ekleyerek stringe çeviriyoruz -> “^ab”. Daha sonra bu alfabenin butün kombinasyonlarını yukarıdaki yöntem ile üretiyoruz. Dolayısıyla üretilen kombinasyon artıyor ancak bizim istediğim bütün kombinasyonlar elde edilmiş oluyor -> aa,ab,ba,bb. Daha sonrasında ise üretilen boş kelime kombinasyonlarını liste dışında tutuyoruz çünkü bizim ihtiyacımız olan boş kelime dışında üretilen kombinasyonlar.Bu şekilde alfabe’nin bütün kombinasyonları üretilebilir.
Aşağıdaki java kodu, gönderilen alfabe (örnek: ‘^ab’) ve gönderilen sayı (örnek:10) ile sayının n’lik tabandaki karşılığını buluyoruz. Bunu yaparken ‘1010’ gibi bir sayı yerine direkt olarak alfabede 1 ve 0 yerine gelen harfleri koyuyoruz( alfabe.charAt(sayi % alfabeLen) ). Şayet gönderilen sayı boş kelimenin bir kombinasyonu ise boş string return ediyoruz. Değilse üretilen kelimenin kendisini return ediyoruz.Bu şekilde bütün sayıları göndererek bütün kombinasyonları üretmiş oluyoruz.
private static String toWord(int sayi,String alfabe){
int alfabeLen = alfabe.length();
String word = "";
while(sayi > 0){
word = word + alfabe.charAt(sayi % alfabeLen);
sayi /= alfabeLen;
}
return word.contains("^") ? "" : word;
}Regular Expression to NFA to DFA
Sorunun çözümünde son aşamaya geldik denilebilir. Artık tek yapmamız gereken verilen düzenli ifadenin otomatını çıkartmak böylece girilen bir stringin o regex’e uygun olup olmadığını kontrol edebiliriz.Peki bunu regex kütüphanesini kullanmadan nasıl yapacağız? Yapmamız gereken şey regex’i dfa’ya dönüştürmek.Böylece DFA’da final state’e gelip gelmediğimizi test ederek sonuca ulaşmız olacağız.Konsepti anlamak için öncelikle bu video izlemeniz gerekli
Yazının bu kısmının daha iyi anlaşılabilmesi için github/alirezakay/regexToDfa ve geeksforgeeks/regexToDfa kişilerinden/sitelerinden alıntılayarak türkçeye çevirmeye çalıştım.Orjinal hallerine linklere tıklayarak ulaşabilirsiniz.Ayrıca derleyici tasarımlarının nasıl gerçekleştiğini anlamak için Compiler Desing Playlist‘ini youtube’dan izleyebilirsiniz.Anlatılan kavramlar derleyicilerin kodu derlerken hangi aşamalardan geçtiğini,hangi yöntemleri kullandıklarını vs. daha detaylı bir biçimde anlatmaktadır.
Örnek: (a|b)*abb
NOT: ( ‘|’ işareti aynı zamanda ‘+’ , ‘veya’ anlamlarına gelmektedir.)
1- Verilen regex’in sonuna ‘#’ işaretini ekliyoruz.Bunun sebebi regex’in sonuna yani final durumuna gelip gelmediğimizi anlamak.
2-Söz dizimi(syntax) ağacını oluşturuyoruz.Daha iyi anlaşılması için aşağıya oluşturduğumuz ağacın görselini ekleyelim.
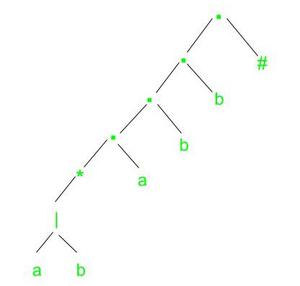
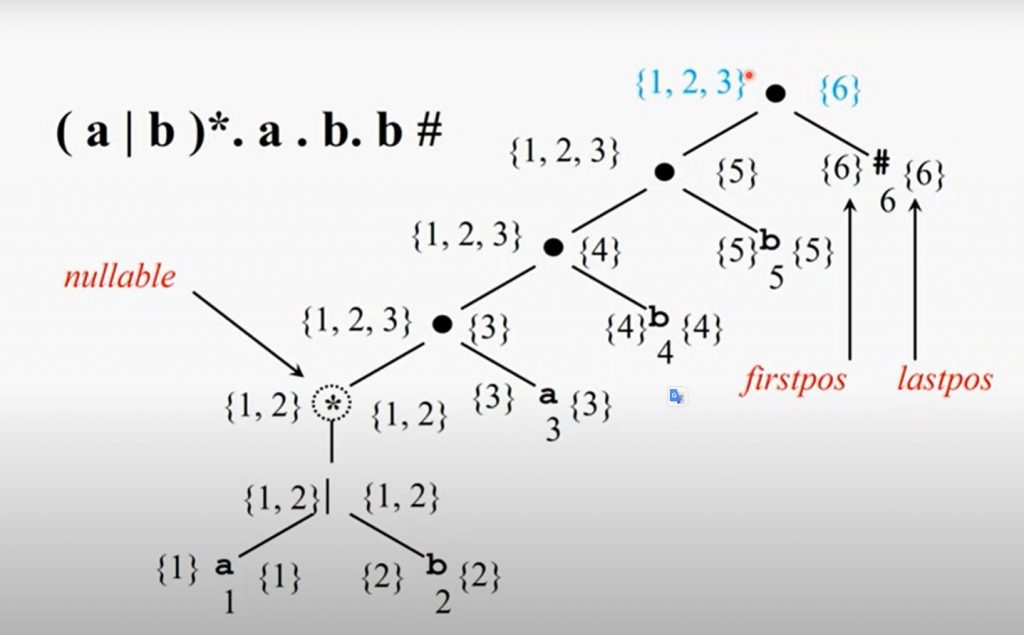
3- Oluşturulan ağacın nullable,firstpos,lastpos ve followpos durumlarını hesaplamamız gerekiyor.Yukarıdaki videoda bunların nasıl hesaplandığıyla ilgili bir video.Aşağıdaki kuralları göz önüne alarak oluşan ağacın bu dört durumunu hesaplıyoruz.

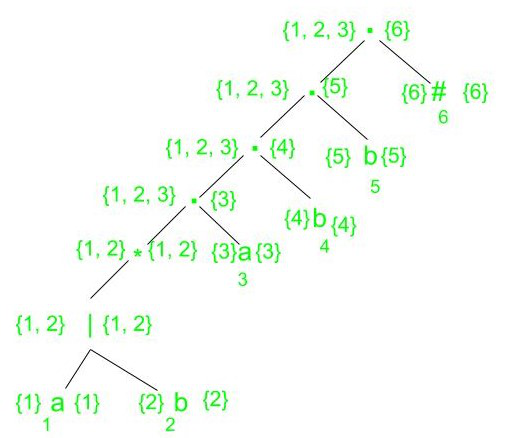
4- (a|b)*abb için firstpos ve lastpos’ları hesaplanmış syntax tree’si aşağıdaki görselde mevcuttur.Nasıl hesaplandıkları videoda daha detaylı bir biçimde anlatılmış ve hesaplanma kuralları yukarıda verilmiştir.
5- Bu adımda ağacın followpos durumu hesaplanacaktır.Ağacı aşağıdan yukarıya olacak şekilde followpos’unu hesaplıyoruz.
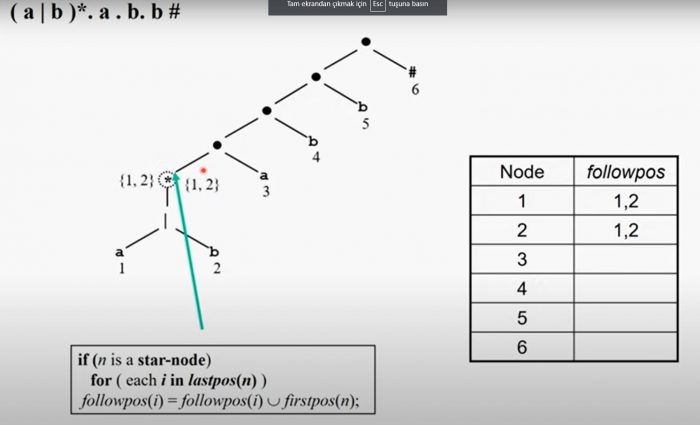

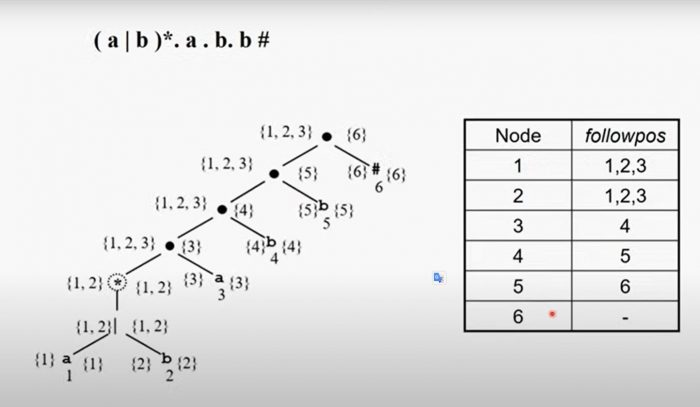
6- Son olarak ağacın başlangıç düğümünden başlayarak otomatını oluşturacağız. Adım adım statelerin ‘a’ için hangi duruma, ‘b’ için hangi duruma gideceğini hesaplayalım.Öncelikle kök düğüm {1,2,3}’den başlıyoruz. 1,2 ve 3 numaralı nodeları kendi aralarında hangi state’e gittiklerine göre eşleştirme yapmamız gerekli 1 ve 3 numara ‘a’ harfine sahip, dolayısıyla 1 ve 3 numaralı nodeların followposlarını birleştirmemiz gerekli.2 numara ‘b’ harfine sahip ve ondan başka ‘b’ olmadığından dolayı sadece 2 numaralı followposu ifade edecek.
Öncelikle 1 ve 3 numaralı düğümlerin followpos’larını birleştirelim. 1 = {1,2,3} , 3 = {4} , 1 ∪ 3 = {1,2,3,4} *AÇIKLAMA: 1 ve 3’ün birleşimi yeni bir state olduğundan dolayı state tablosuna ekleme yapıyoruz. Yani {1,2,3} ‘a’ durumuna giderken {1,2,3,4}’e gidiyor.
Şimdi de 2 numaralı düğümün followpos’una bakalım. 2 = {1,2,3}, 2 ∪ 2 = {1,2,3} *AÇIKLAMA: {1,2,3} zaten state tablosunda mevcut. Böylece {1,2,3} ‘b’ durumuna giderken {1,2,3}’e yani kendisine gidiyor.
6.1- Bir adım daha ilerleyerek tablonun gidişatına bakalım.Sırada {1,2,3,4} numaralı state var. State’in içerisindeki nodeları kendi aralarında gruplayalım.1 ve 3 numara ‘a’, 2 ve 4 numara ‘b’ye sahip.
1 ve 3’ü daha önce birleştirmiştik. 1 ∪ 3 = {1,2,3,4}. Böylece {1,2,3,4} numaralı state ‘a’ ya giderken {1,2,3,4}’e yani kendine dönmüş oluyor.
2 ve 4’ü birleştirelim. 2 = {1, 2, 3} , 4 = {5}. 2 ∪ 4 = {1,2,3,5}. Yeni oluşan state, tablomuzda olmadığından dolayı tabloya ekliyoruz. {1,2,3,4} numaralı state ‘b’ye giderken {1,2,3,5}’e gitmiş oluyor.
Bu şekilde durumları sona getirene kadar dolduralım ayrıca state tablomuzdaki state’leri isimlendirmemiz yazmada bize kolaylık sağlayacaktır.İsterseniz state isimlendirme yöntemini uygulayabilirsiniz.
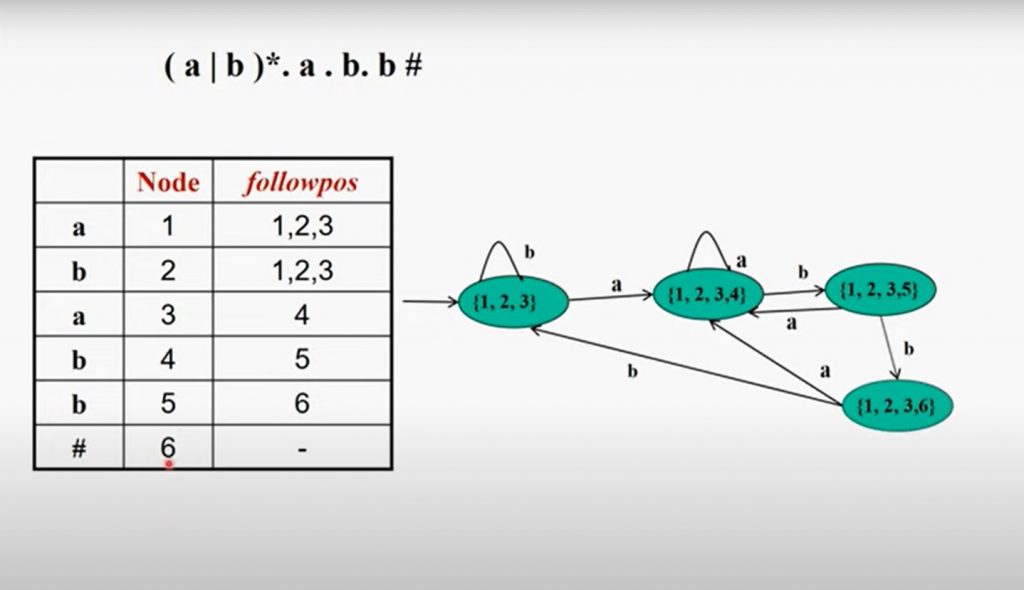
Final state’i ‘#’ işaretini içeren bütün statelerdir dolayısıyla şekilde görülen {1,2,3,6} final statedir.Böylece sona gelmiş oluyoruz. Bütün durumları çıkarttık ve regex’e uygun DFA’mızı oluşturmuş olduk. Artık gelen stringleri otomat üzerinde test edebilir ve uygun olup olmadığını kontrol edebiliriz.
Kodlara github aracılığı ile erişebilirsiniz: https://github.com/nurullahturkoglu/generate-strings-from-regex
Bu yazı uzun emekler sonucu tamamen sizlere faydalı olması açısından yazılmıştır.Düşünceleriniz ve fikirleriniz benim ve gelecek yazılar için önemli.Lütfen yorum yapmaktan çekinmeyin.Umarım faydalı olabilmişimdir.Okuduğunuz için teşekkür ederim.